Scatter Diagram and Correlation Coefficient
## Scatter Diagram and Correlation Coefficient
### Scatter Diagram
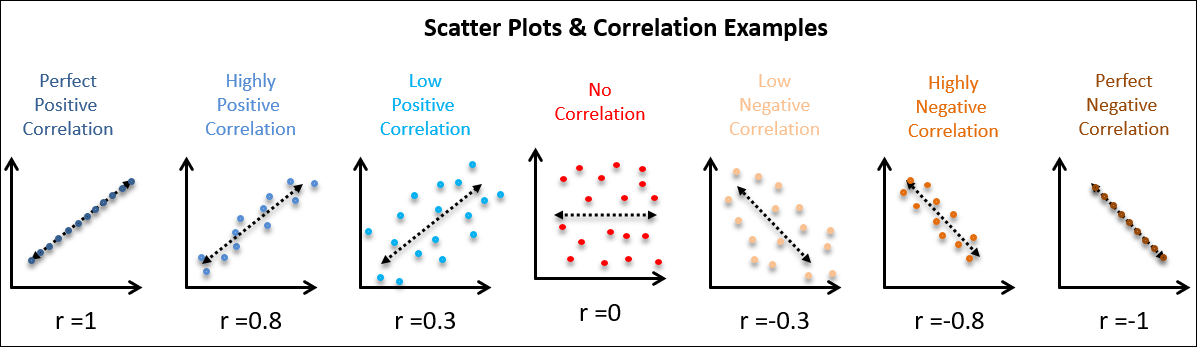
A **scatter diagram** (or scatter plot) is a graphical representation that displays the relationship between two quantitative variables. Each point on the scatter plot corresponds to an observation in the dataset, with one variable plotted along the X-axis and the other along the Y-axis. This visual representation helps to identify patterns, trends, and potential correlations between the variables.
#### Key Features:
- **Axes**: The horizontal axis (X-axis) typically represents the independent variable, while the vertical axis (Y-axis) represents the dependent variable.
- **Data Points**: Each point on the diagram represents a pair of values from the two variables being analyzed.
- **Correlation Identification**: The pattern of the plotted points indicates the nature of the relationship:
- **Positive Correlation**: Points trend upwards from left to right, indicating that as one variable increases, the other also tends to increase.
- **Negative Correlation**: Points trend downwards from left to right, indicating that as one variable increases, the other tends to decrease.
- **No Correlation**: Points are scattered without any discernible pattern, suggesting no relationship between the variables.
### Correlation Coefficient
The **correlation coefficient** quantifies the strength and direction of the relationship between two variables. The most commonly used correlation coefficient is **Pearson's correlation coefficient (r)**, which ranges from -1 to +1.
#### Interpretation of Pearson's Correlation Coefficient:
- **+1**: Perfect positive correlation. As one variable increases, the other variable increases perfectly in a linear fashion.
- **0**: No correlation. Changes in one variable do not predict changes in the other variable.
- **-1**: Perfect negative correlation. As one variable increases, the other variable decreases perfectly in a linear fashion.
### Interpretation in a Sociological Study
In a sociological context, interpreting Pearson's correlation coefficient involves understanding the implications of the relationship between two social variables. For example, consider a study examining the relationship between education level (measured in years) and income (measured in dollars).
1. **Positive Correlation (e.g., r = 0.8)**:
- Interpretation: There is a strong positive correlation between education level and income. This suggests that as education level increases, income tends to increase as well. This finding could support policies aimed at increasing educational access as a means to improve economic outcomes.
2. **No Correlation (e.g., r = 0.0)**:
- Interpretation: There is no correlation between education level and income. This could indicate that other factors, such as job market conditions or personal circumstances, play a more significant role in determining income than education alone.
3. **Negative Correlation (e.g., r = -0.5)**:
- Interpretation: A moderate negative correlation might suggest that as one variable increases, the other decreases. For example, if the study found a negative correlation between hours spent on social media and academic performance, it could imply that increased social media use may be associated with lower academic achievement.
### Conclusion
Scatter diagrams and correlation coefficients are essential tools in sociological research for visualizing and quantifying relationships between variables. By interpreting Pearson's correlation coefficient, researchers can draw meaningful conclusions about the nature and strength of associations, informing both theoretical understanding and practical policy implications.
Citations:
[1] https://www.vedantu.com/commerce/scatter-diagram
[2] https://byjus.com/commerce/scatter-diagram/
[3] https://asq.org/quality-resources/scatter-diagram
[4] https://www.geeksforgeeks.org/scatter-diagram-correlation-meaning-interpretation-example/
[5] https://byjus.com/maths/scatter-plot/
[6] https://en.wikipedia.org/wiki/Spearman%27s_rank_correlation_coefficient
[7] https://www.westga.edu/academics/research/vrc/assets/docs/ChiSquareTest_LectureNotes.pdf
[8] https://byjus.com/maths/chi-square-test/