Rationale for Analyzing Ordinal-Scale Data
## Rationale for Analyzing Ordinal-Scale Data
Ordinal-scale data is characterized by its ranking order, where the values indicate relative positions but do not specify the magnitude of differences between them. Analyzing ordinal data is important in sociological research for several reasons:
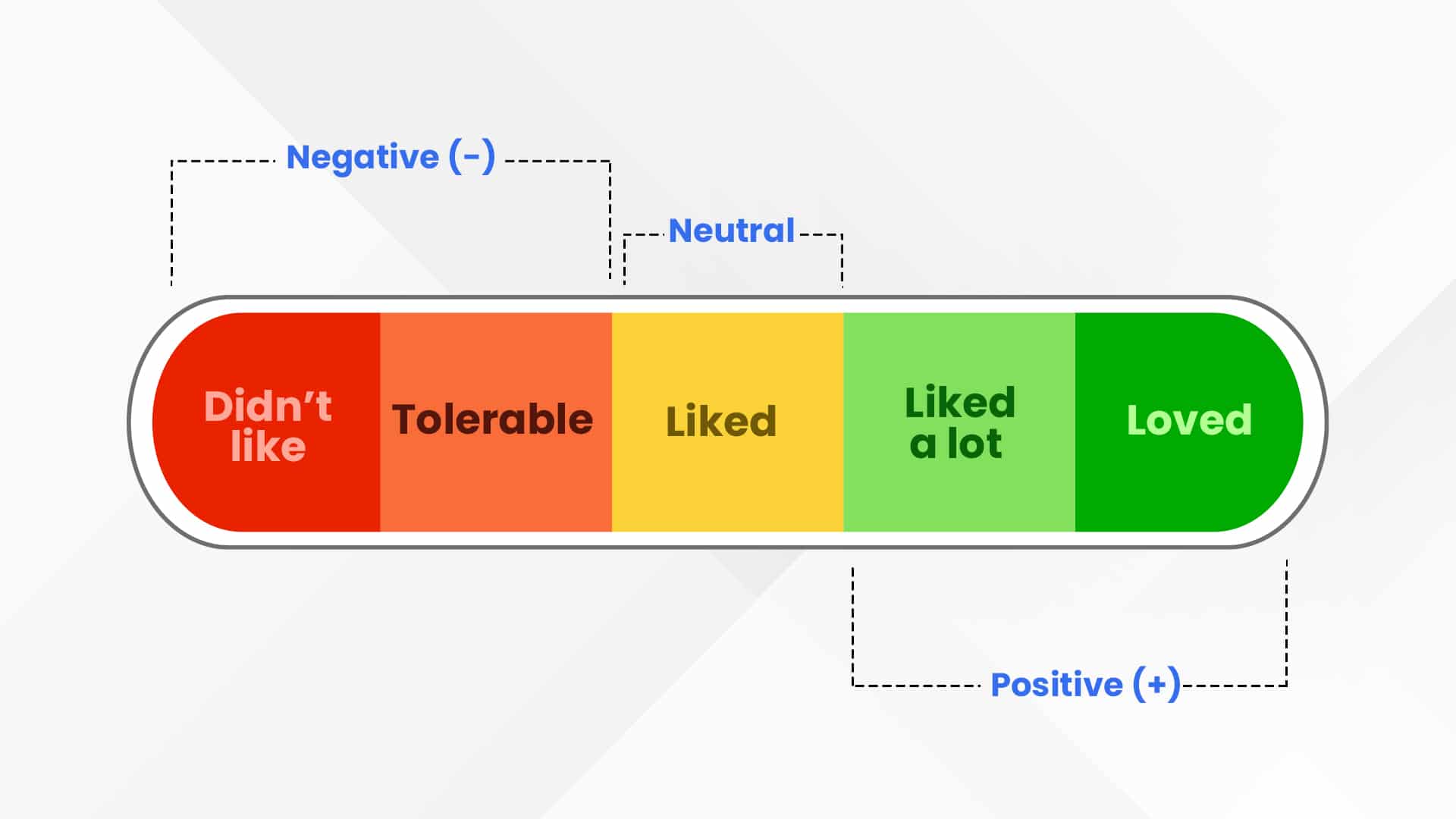
1. **Capturing Order**: Ordinal data allows researchers to capture the order of responses or observations, which is crucial in understanding preferences, attitudes, or levels of agreement. For example, survey responses such as "strongly agree," "agree," "neutral," "disagree," and "strongly disagree" provide valuable insights into public opinion.
2. **Flexibility in Analysis**: Ordinal data can be analyzed using non-parametric statistical methods, making it suitable for situations where the assumptions of parametric tests (like normality) are not met. This flexibility enables researchers to draw meaningful conclusions from a wider range of data types.
3. **Comparative Analysis**: By ranking data, researchers can compare groups or conditions more effectively. For instance, analyzing customer satisfaction ratings across different service providers can highlight which provider is perceived as the best or worst.
4. **Understanding Trends**: Analyzing ordinal data can reveal trends over time or across different groups. For example, tracking changes in public health perceptions before and after a health campaign can inform future interventions.
### Interpreting the Results of a Rank Correlation Coefficient
The rank correlation coefficient, such as Spearman's rank correlation coefficient, is used to assess the strength and direction of the relationship between two ordinal variables. Here’s how to interpret the results:
1. **Coefficient Range**: The rank correlation coefficient (denoted as $$ \rho $$ or $$ r_s $$) ranges from -1 to +1.
- **+1** indicates a perfect positive monotonic relationship, meaning as one variable increases, the other variable also increases consistently.
- **-1** indicates a perfect negative monotonic relationship, where an increase in one variable corresponds to a decrease in the other.
- **0** indicates no correlation, suggesting that changes in one variable do not predict changes in the other.
2. **Strength of the Relationship**: The closer the coefficient is to +1 or -1, the stronger the relationship between the two variables. For example:
- A coefficient of **0.8** suggests a strong positive correlation, indicating that higher ranks in one variable are associated with higher ranks in the other.
- A coefficient of **-0.3** suggests a weak negative correlation, indicating a slight tendency for higher ranks in one variable to be associated with lower ranks in the other.
3. **Monotonic Relationships**: It is essential to note that the Spearman rank correlation assesses monotonic relationships, meaning the relationship does not have to be linear. This makes it particularly useful for ordinal data, where the exact differences between ranks are not known.
4. **Causation vs. Correlation**: While a significant rank correlation indicates a relationship between the two variables, it does not imply causation. Researchers must be cautious in interpreting the results and consider other factors that may influence the observed relationship.
5. **Statistical Significance**: The significance of the correlation coefficient can be tested using hypothesis testing. A p-value is calculated to determine whether the observed correlation is statistically significant. A common threshold for significance is $$ p < 0.05 $$, indicating that there is less than a 5% probability that the observed correlation occurred by chance.
### Conclusion
Analyzing ordinal-scale data is vital in sociological research as it captures the ranking of responses and allows for flexible statistical analysis. The rank correlation coefficient, such as Spearman's $$ \rho $$, provides a valuable tool for interpreting relationships between ordinal variables, helping researchers understand trends and associations while being mindful of the distinction between correlation and causation.
Citations:
[1] https://www.technologynetworks.com/tn/articles/spearman-rank-correlation-385744
[2] https://study.com/academy/lesson/spearman-s-rank-correlation-coefficient.html
[3] https://www.simplilearn.com/tutorials/statistics-tutorial/spearmans-rank-correlation
[4] https://en.wikipedia.org/wiki/Spearman%27s_rank_correlation_coefficient
[5] https://journals.lww.com/anesthesia-analgesia/fulltext/2018/05000/correlation_coefficients__appropriate_use_and.50.aspx
[6] https://www.statstutor.ac.uk/resources/uploaded/spearmans.pdf
[7] https://statistics.laerd.com/statistical-guides/spearmans-rank-order-correlation-statistical-guide-2.php
[8] https://datatab.net/tutorial/spearman-correlation





